數據就是資產:DataFi 正引領新藍海的開啟
「我們正處於全球爭相打造最佳基礎模型的年代。雖然運算能力與模型架構舉足輕重,真正的護城河在於訓練資料。」
——Sandeep Chinchali,Story 首席 AI 官
從 Scale AI 看 AI Data 賽道潛力
本月 AI 圈最引人矚目的八卦,無疑就是 Meta 展現雄厚財力,馬克·祖克柏大舉招募人才,打造以華人科研人才為主力的頂尖 Meta AI 團隊。團隊領航者是年僅 28 歲、創辦 Scale AI 的 Alexander Wang。他一手建立的 Scale AI,如今估值高達 290 億美元,服務對象涵蓋美國軍方及 OpenAI、Anthropic、Meta 等多家競爭激烈的 AI 巨頭,全數仰賴 Scale AI 提供數據服務;而 Scale AI 的核心業務,正是提供大量高精度的標註資料(labeled data)。
為什麼 Scale AI 能從眾多獨角獸中脫穎而出?
關鍵在於它很早就洞悉,數據對 AI 產業的關鍵地位。
算力、模型、資料,是 AI 模型的三大支柱。若將大模型比作一個人,模型為身體、算力是食物,而資料即是知識與訊息。
在 LLM 崛起至今,業界發展重點已從模型轉向算力,多數模型框架皆採 Transformer,間或出現 MoE、MoRe 等新意;各大巨頭要嘛自建 Super Cluster 完成運算基石,要嘛與 AWS 等雲端巨頭簽訂長約;當基礎算力逐步到位,數據的重要性隨之顯現。
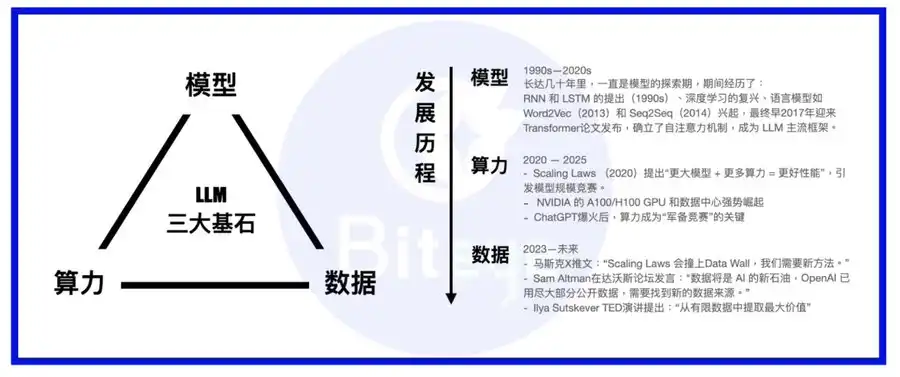
與 Palantir 等上市傳統 To B 大數據公司不同,Scale AI 顧名思義,聚焦於為 AI 模型建立堅實資料基礎,業務涵蓋現有資料深度挖掘與前瞻性的數據生成,並聚合來自各專業領域的 AI trainer 團隊,為 AI 訓練提供品質更勝一籌的訓練資料。
如果你對這項業務無感,不妨看看模型訓練究竟如何運作。
模型訓練分為兩大階段——預訓練與微調。
預訓練好比人類嬰兒學語言,需大量網路爬蟲文本、程式碼等原始資料餵養 AI,經模型自我學習後,具備基本語言理解溝通能力(即自然語言處理)。
微調則如同進校園學習,講求明確的對錯、標準答案與方向。不同學校有不同養成規劃,我們則以精心處理、標註的資料集,將模型訓練出預期功能。

由此你也許能意會到,AI 所需資料可概分為兩大類:
· 第一類資料毋需過多處理,數量充足即可,來源涵蓋 Reddit、Twitter、GitHub 等大型 UGC 平台爬蟲數據、開放文獻資料庫、企業私有資料庫等。
· 第二類如專業教科書,要精緻設計、嚴格篩選,才能養成模型某些特質,這需要資料清洗、篩選、標記、人工回饋等程序。
兩大資料集構成 AI Data 賽道主體。別小看這些看似技術含量不高的資料集,目前主流觀點一致認為,隨 Scaling laws 下算力紅利遞減,「資料」將成為大型 AI 模型維持競爭優勢的決定性基石。
隨著模型能力加速進步,更多細緻、專業的訓練資料將主導模型關鍵能力。若把模型養成比喻為武林高手修煉,頂級資料集就是至尊武功祕笈(進一步比喻,算力為靈丹妙藥,模型為自身資質)。
由長遠來看,AI Data 亦屬於具備滾雪球效應的長期型賽道,隨早期投入累積,資料資產將產生複利,愈老愈具價值。
Web3 DataFi:AI Data 最佳沃土
相較 Scale AI 在菲律賓、委內瑞拉等地以遠距團隊雇用數十萬標記人員,Web3 在 AI 數據領域具備天然優勢,「DataFi」由此誕生。
理想狀況下,Web3 DataFi 具備以下優勢:
1. 智能合約保障資料主權、安全與隱私
隨公有數據逐漸枯竭,挖掘未公開甚至隱私數據成為資料源拓展關鍵。其中信任選擇尤重要——你要和集中式大公司簽一次性賣斷合約,出賣自己所有的數據,還是選擇區塊鏈方式,持續保有資料 IP,並能清楚掌握數據被什麼人、何時、用於何事?
對於敏感資料,還能利用 zk、TEE 等技術,確保個人資訊只由保密的機器處理,不會外洩。
2. 天生地理套利:去中心化架構吸引全球最合適人力
或許正該顛覆傳統勞動關係。比起像 Scale AI 四處尋找低價勞動力,不如發揮區塊鏈分散特性,利用智能合約保障公開透明激勵,讓全球各地勞動力都能公平參與資料貢獻。
針對資料標註、模型評估等人力密集型工作,相較集中式數據工廠,Web3 DataFi 參與者多元,長遠來說也能減少資料偏見。
3. 區塊鏈激勵及結算清楚明確
如何避免「江南皮革廠」式悲劇?當然要靠智能合約明碼標價的激勵制度,徹底杜絕人性黑暗。
在去全球化大勢下,怎維持低成本地理套利?世界各地設公司門檻愈來愈高,直接採用鏈上結算成為新解方。
4. 有助建立高效且公開透明的「一條龍」資料市場
「中間商賺差價」始終令人詬病,與其被中心化資料公司剝削,不如自行在鏈上搭建平台,仿效淘寶式公開市場,促使資料需求與供給直接高效對接。
隨鏈上 AI 生態茁壯,鏈上資料需求將更加多元、細分且旺盛。唯有去中心化市場才能靈活消化這些需求,帶動整體生態繁榮。
對散戶來說,DataFi 也是最適合一般用戶參與的去中心化 AI 專案
雖然 AI 工具誕生確實降低門檻,去中心化 AI 的初衷更在於打破巨頭壟斷;但不可否認,許多專案對零技術背景小白相當不友善——參與去中心化算力挖礦幾乎必須先砸重金買硬體,模型市場技術門檻又高的讓人卻步。
反觀 DataFi,卻是一般用戶在 AI 革命浪潮裡,僅存的參與窗口——Web3 讓你不用為「資料血汗工廠」合約綁身,只需滑鼠點擊登入錢包,即能完成各式簡單任務,包括:貢獻資料、用人腦直覺標記或評估模型、運用 AI 工具簡單創作、參與資料交易等。只要懂「套利」訣竅,難度堪稱零門檻。
Web3 DataFi 代表性潛力專案
資金流向即趨勢所在。除了 Web2 領域的 Scale AI 獲 Meta 投資 143 億美元、Palantir 股價單年暴漲 5 倍外,Web3 融資領域中,DataFi 賽道表現同樣搶眼。以下簡介主流專案:
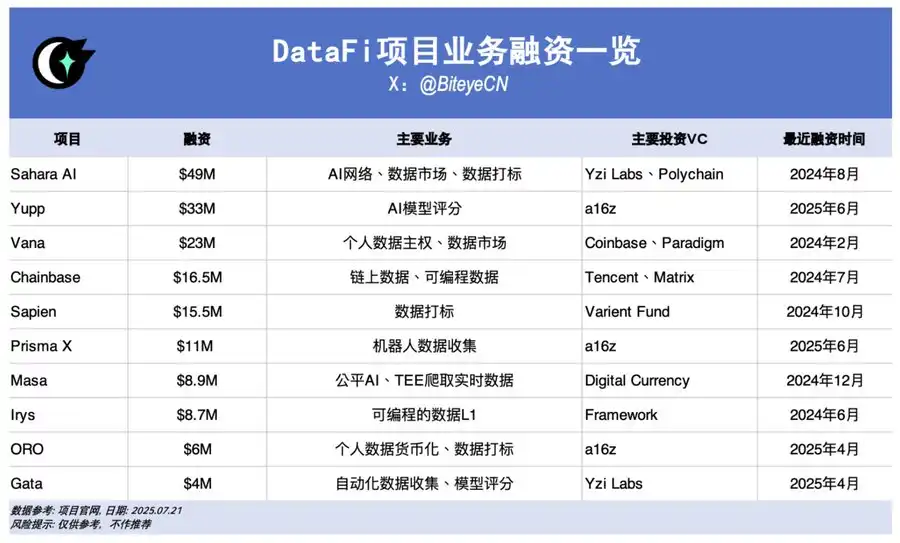
Sahara AI,@SaharaLabsAI,融資 4900 萬美元
Sahara AI 目標打造去中心化 AI 的超級基礎設施與交易市場,率先試水便著眼於 AI Data,其 DSP(Data Services Platform,資料服務平台)公測版將於 7 月 22 日上線,使用者可透過貢獻資料、參與標註等任務來賺取代幣獎勵。
連結:app.saharaai.com
Yupp,@yupp_ai,融資 3300 萬美元
Yupp 是 AI 模型用戶反饋平台,專注蒐集用戶對模型輸出表現的意見。現階段主要任務係對比不同模型對同一 prompt 輸出,評選較佳者。完成任務可獲 Yupp 積分,積分可兌換 USDC 等穩定幣。
Vana,@vana,融資 2300 萬美元
Vana 專注將個人數據(如社群媒體紀錄、瀏覽資料等)轉變為可流通數位資產。使用者可授權將個人資料匯入 DataDAOs 對應的資料流動池(DLP),這些資料將參與 AI 模型訓練,使用者也會獲得相應代幣獎勵。
連結:https://www.vana.org/collectives
Chainbase,@ChainbaseHQ,融資 1650 萬美元
Chainbase 專攻鏈上資料,現已覆蓋 200 條以上區塊鏈,將區塊鏈上行為轉換為結構化、可驗證且可流通的資料資產,供 dApp 開發應用。主營多鏈索引,經 Manuscript 系統及 Theia AI 模型處理資料,目前使用者參與情形不高。
Sapien,@JoinSapien,融資 1550 萬美元
Sapien 致力於將人類知識大規模轉化為高品質 AI 訓練資料,所有使用者皆可參與資料標註,並採同儕審核機制確保數據品質。同時鼓勵建立長期信譽、或以質押作承諾,賺取更高獎勵。
連結:https://earn.sapien.io/#hiw
Prisma X,@PrismaXai,融資 1100 萬美元
Prisma X 致力機器人開放協調層,其中物理資料蒐集扮演關鍵。該專案仍屬早期,據最新白皮書,參與方式可能包括投資機器人資料蒐集、遠端遙控蒐集等。現已開啟基於白皮書的 quiz 活動,開放參與賺積分。
連結:https://app.prismax.ai/whitepaper
Masa,@getmasafi,融資 890 萬美元
Masa 為 Bittensor 生態領頭子網之一,目前有 42 號資料子網及 59 號 Agent 子網。資料子網主打提供即時存取資料,目前礦工主要藉 TEE 硬體爬取 X/Twitter 即時數據,對一般使用者來說參與門檻與成本較高。
Irys,@irys_xyz,融資 870 萬美元
Irys 聚焦可編程資料儲存與運算,旨在為 AI、去中心化應用(dApps)及其他資料密集型場景提供高效、低成本解決方案。資料貢獻方面目前看使用者參與情形不高,但當前測試網階段有多重活動可以參與。
ORO,@getoro_xyz,融資 600 萬美元
ORO 致力賦能一般人參與 AI 貢獻。支援方式有:1. 綁定個人帳戶貢獻數據(如社群帳號、健康、電商金融等);2. 執行資料任務。目前測試網已開放,使用者可直接上線參與。
連結:app.getoro.xyz
Gata,@Gata_xyz,融資 400 萬美元
Gata 為去中心化資料層,現已推出三大產品參與方式:1. Data Agent:只需打開網頁即可自動運行處理資料的 AI Agent;2. All-in-one Chat:類似 Yupp 的模型評比獎勵機制;3. GPT-to-Earn:瀏覽器外掛,收集使用者在 ChatGPT 上的對話資料。
連結:https://app.gata.xyz/dataAgent
https://chromewebstore.google.com/detail/hhibbomloleicghkgmldapmghagagfao?utm_source=item-share-cb
如何評價這些專案?
目前這些專案技術門檻普遍不高,但要明白,一旦用戶量與生態黏著度積累,平台優勢將極速放大,因此初期務必在激勵政策、用戶體驗著力,唯有吸引足夠用戶才能壯大數據生意。
不過,作為人力密集型平台,這些資料專案在吸引人力同時,也需考量管理與資料品質保障。Web3 眾多專案通病——平台九成用戶偏好短線套利,往往不顧品質,若放任其主導,恐導致劣幣驅逐良幣,數據品質難以穩定,最終也難以吸引真實需求方。近期像 Sahara、Sapien 等專案皆已強化資料品質管理,積極建立平台與人工間的長期合作機制。
另外,鏈上專案透明度不足亦是個痛點。誠然,區塊鏈「不可能三角」使許多專案初期採權宜「中心化推動去中心化」路線,但不少鏈上專案實際給人「Web3 皮下 Web2 骨」的觀感——公開鏈上資料極少,長期路線圖亦鮮見公開透明決心。這對 Web3 DataFi 長期健康發展有負面影響,呼籲更多專案堅守初心,加速邁向公開透明。
最後,DataFi 大規模普及路徑分兩面向:一是吸引廣大 toC 參與者加入,成為資料收集、AI 經濟的基礎動力,建立生態閉環;二是獲得主流 toB 企業認可,畢竟現階段大訂單主要仍來自財力雄厚企業。這部分,Sahara AI、Vana 等專案皆已取得亮眼成果。
結語
用「宿命論」來說,DataFi 就是人類智慧持續哺育機器智能,智能合約作為勞動契約,保障人類知識產出獲得回報,最終也將受惠於機器反哺。
如果你正為 AI 時代不確定性感到焦慮、在幣圈跌宕起伏卻仍堅持區塊鏈理想,不妨跟隨資本領袖腳步,加入 DataFi,順勢而為、擁抱新機會。
聲明:
- 本文轉載自 [BLOCKBEATS],著作權歸原作者 [anci_hu49074,Biteye 核心貢獻者] 所有,如對轉載有疑義,請聯絡 Gate Learn 團隊,團隊將依流程儘速處理。
- 免責聲明:本文所述觀點僅代表作者個人立場,並不構成任何投資建議。
- 文章其他語言版本由 Gate Learn 團隊負責翻譯,未經註明 Gate,不得複製、傳播或抄襲經翻譯文章。
相關文章

Solana需要 L2 和應用程式鏈?

Sui:使用者如何利用其速度、安全性和可擴充性?

錯誤的鉻擴展程式竊取分析

由幣安實驗室支持的必試專案,提供額外權益質押獎勵(包括分步指南)

在哪種敘事中最受歡迎的掉落?
